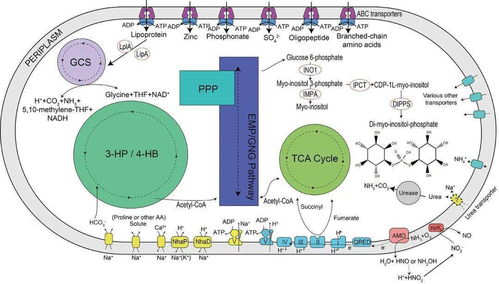
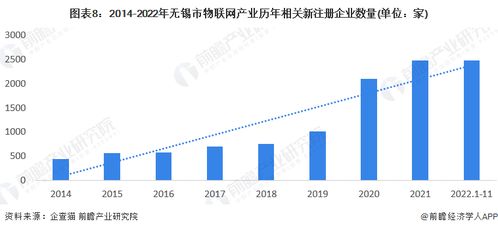
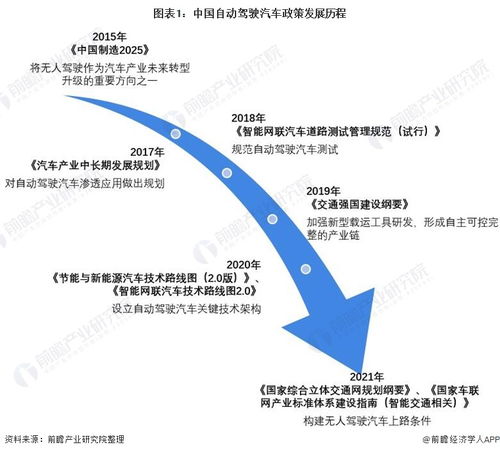
網頁抓取(Web Scraping)和網頁爬取(Web Crawling)是兩種常見的數據獲取方式,雖然它們經常被混用,但在技術實現和應用場景上存在明顯差異。在自然科學的研究與試驗發(fā)展中,這兩種技術都發(fā)揮著重要作用,但各有側重。
網頁抓取與網頁爬取的核心區(qū)別
1. 定義與范圍
網頁爬取通常指系統(tǒng)性地遍歷互聯(lián)網,收集大量網頁的URL和內容,如搜索引擎(如Google、百度)所使用的爬蟲程序。它關注廣度,目標是盡可能多地發(fā)現和索引網頁。
網頁抓取則更側重于從特定網頁中提取結構化數據,例如價格信息、新聞標題或科學數據。它關注深度,通常針對已知的網頁進行數據提取。
2. 技術實現
網頁爬取通常包括URL隊列管理、去重、遵守robots.txt協(xié)議等步驟,以確保高效且合規(guī)地遍歷網站。
網頁抓取則依賴于解析HTML結構(如使用XPath或CSS選擇器)來定位和提取所需數據,有時還需處理JavaScript渲染的內容。
3. 應用場景
網頁爬取適用于構建搜索引擎、網站地圖或大規(guī)模數據采集項目。
網頁抓取更適用于數據挖掘、競爭情報分析或特定領域的監(jiān)控(如天氣數據、科研論文摘要)。
在自然科學研究與試驗發(fā)展中的應用
在自然科學領域,網頁抓取和網頁爬取技術為科研人員提供了高效的數據支持:
1. 數據采集與整合
科研人員可通過網頁爬取收集公開的科學數據庫(如PubMed、arXiv)中的論文摘要和元數據,用于文獻綜述或趨勢分析。
網頁抓取則可用于提取特定實驗數據,如氣象站記錄的溫濕度、基因序列數據庫中的特定信息,或化學物質屬性表。
2. 實時監(jiān)測與預測
在環(huán)境科學中,抓取實時空氣質量或水質數據可輔助污染模型構建;在生物學中,爬取全球生物多樣性數據庫有助于物種分布研究。
3. 試驗設計與驗證
通過抓取歷史實驗數據,研究人員可優(yōu)化試驗方案。例如,在材料科學中,提取已知材料的性能參數可加速新材料開發(fā)。
4. 合規(guī)性與倫理
自然科學應用需嚴格遵守數據使用協(xié)議,避免侵犯版權或違反網站條款。例如,爬取受限數據庫可能需獲得授權,而抓取公共數據時也需注意數據源的引用規(guī)范。
總結
網頁抓取和網頁爬取雖在技術上有所重疊,但其核心差異在于目標與范圍:爬取注重廣度,抓取注重深度。在自然科學研究與試驗發(fā)展中,兩者結合使用可大幅提升數據獲取效率,推動科學發(fā)現與技術創(chuàng)新。科研人員必須確保操作合法合規(guī),以維護學術倫理和數據安全。